
This is part of the Beyond The Shiny New Toys series where I write about AWS reInvent 2019 announcements
AWS ecosystem around containers is pretty large. It comprises of AWS’ own orchestration engine, managed Kubernetes control planes, serverless container platforms, ability to run large scale batch workloads on containers. And a whole lot of deep integrations with rest of the AWS ecosystem for storage, logging, monitoring, security to name a few.
AWS re:Invent 2019 saw quite a few announcements around containers. These announcements further simplify deploying and managing container workloads. Here are some of them that I liked.
AWS Fargate for Amazon EKS
https://aws.amazon.com/blogs/aws/amazon-eks-on-aws-fargate-now-generally-available/
When EKS was launched last year, we saw this coming eventually. And here it is. You can now launch Kubernetes Pods on AWS Fargate with absolutely no infrastructure to manage.
With Amazon EKS, AWS offered a managed Kubernetes control plane. This definitely solved a major pain point of dealing with all the moving parts (etcd!) of the Kubernetes control plane. However, customers still had to manage the worker nodes (where containers actually run) of the cluster – such as scaling them, patching them or keeping them secure.
AWS Fargate is a fully managed, serverless offering from AWS to run containers at scale. AWS completely manages the underlying infrastructure for your containers (like AWS Lambda). Similar to Lambda, you only pay based on the memory, CPU used by your containers and how long the container ran.
Fargate Profile
One of the aspects that I liked about this launch is “Fargate Profile”. With a Fargate Profile, you can declare which Kubernetes pods you would like to be run on Fargate and which ones on your “own” EC2 based worker nodes. You can selectively schedule pods through Kubernetes “Namespace” and “Labels”.
This means, with a single Kubernetes control plane (managed by EKS), an administrator can selectively schedule Kubernetes pods between Fargate and “EC2” based worker nodes. For example, you could have your “test/dev” workloads running on Fargate and “prod” workloads (where you may need more control for security/compliance) running on EC2 based worker nodes.
Here’s an example Fargate Profile:
{
"fargateProfileName": "fargate-profile-dev",
"clusterName": "eks-fargate-test",
"podExecutionRoleArn": "arn:aws:iam::xxx:role/AmazonEKSFargatePodExecutionRole",
"subnets": [
"subnet-xxxxxxxxxxxxxxxx",
"subnet-xxxxxxxxxxxxxxxx"
],
"selectors": [
{
"namespace": "dev",
"labels": {
"app": "myapp"
}
}
]
}With the above fargate profile, pods in the namespace “dev” with labels “app”:”myapp” will automatically get scheduled on Fargate. Rest of the pods will get scheduled on EC2 worker nodes.
All without any changes from the developer perspective – they deal only with Kubernetes objects without polluting those definitions with any Fargate specific configurations. Kudos to the AWS container services team for coming with such a clean design.
Note: AWS ECS also works on a similar model through Launch Types. However, ECS control plane is AWS propreitary and they would have all the freedom to offer something like this. Offering something similar to Kubernetes is truly commendable
AWS Fargate Spot
https://aws.amazon.com/blogs/aws/aws-fargate-spot-now-generally-available/
I guess it’s self explanatory. You get “Spot Instances” type capabilities in Fargate now. With “Termination Notification” to your Tasks. This translates to significant cost savings for workloads that can sustain interruption. You can read more about it in the above blog. However, I have mentioned it here as it serves as a pre-cursor for the next couple of new features that we are going to look at.
Amazon ECS Capacity Providers
https://aws.amazon.com/about-aws/whats-new/2019/12/amazon-ecs-capacity-providers-now-available/
Capacity Providers, as the name suggests deal with providing compute capacity for the containers running on ECS. Previously, for ECS clusters on EC2, customers typically deploy an AutoScalingGroup to manage (and scale) the underlying EC2 Capacity or use Fargate (you control through Launch Types).
With Capacity Providers, customers now have the ability to attach different Capacity Providers for both ECS on EC2 and ECS on Fargate. A single ECS Cluster can have multiple Capacity Providers attached to it. We can also create weights across Capacity Providers (through Capacity Provider Strategy) to distribute ECS Tasks between different Capacity Providers (such as On-demand and Spot Instances).
That sounds a bit complicated? Why is AWS even offering this? What use cases does it solve? Let’s look at a few:
Distribution between On-demand Spot Instances
Let’s say you want to mix On-demand and Spot Instances in your cluster to maintain availability and derive cost savings. Your ECS Cluster can have two Capacity Providers – one comprising of an AutoScalingGroup1 with On-demand Instances and another comprising of an AutoScalingGroup2 with Spot Instances. You can then assign different weights between these Capacity Providers controlling how much percentage Spot Instances you are willing to utilize. In the below example, you have 30% Spot and 70% On-demand Instances by assigning weights 1 and 2 to respective Capacity Providers.
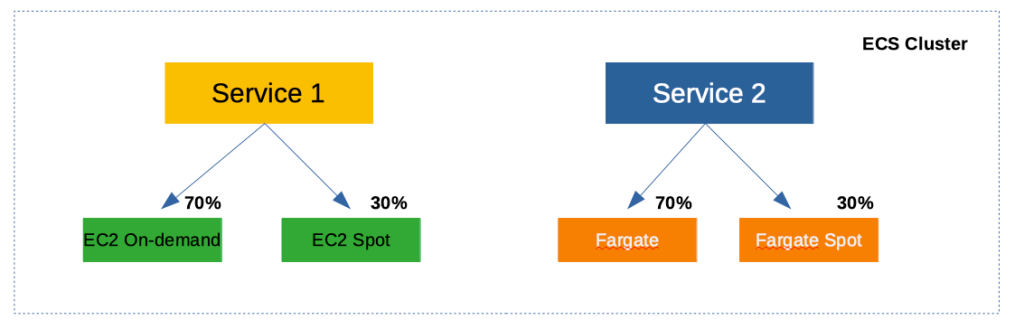
Fargate and Fargate Spot
Just like EC2, Fargate also becomes a Capacity Provider for your cluster. Which means, you can extend the above concept to control how much Fargate Spot you would want in your cluster.
Better spread across Availability Zones
Extending the “weights” that you can assign to Capacity Providers, you can now get better spread of “ECS Tasks and Services” across Availability Zones. For example, you could create 3 Capacity Providers (each having an AutoScalingGroup tied to a single Availability Zone) with equal weights and ECS would take care of evenly spreading your Tasks.
This wasn’t possible earlier because ECS and the underlying AutoScalingGroup weren’t aware of each other. Earlier, you would create a single AutoScalingGroup that is spread across multiple Availability Zones making sure the EC2 Instances are spread across AZs. However, when ECS scheduler runs your “Tasks” it doesn’t necessarily spread the “Tasks” evenly across AZs.
Even spreading of “Tasks” through CapacityProviders is now possible as ECS can now manage the underlying AutoScalingGroup as well through “Managed Cluster Auto Scaling” (a new feature described below).
ECS Managed Cluster Auto Scaling
https://aws.amazon.com/about-aws/whats-new/2019/12/amazon-ecs-cluster-auto-scaling-now-available/
Prior to the launch of this feature, ECS did not have the capability to manage the underlying AutoScalingGroup. You created the ECS cluster separately and the AutoScalingGroup for the underlying Instances separately. The AutoScalingGroup scaled based on the metrics of “tasks” (such as CPU) that are “already running” on the cluster.
So what’s the challenge with this type of scaling?
When you create your “Service” in ECS, you can setup AutoScaling for the service. For example, you can setup a Target Tracking Scaling Policy, that tracks the metrics of your running “Tasks” (of the Service) and scale the number of “Tasks” based on those metrics. This works similar to AutoScaling of EC2 Instances.
However, what about the scenario when your “Service” on ECS scales, but there is insufficient underlying capacity as the EC2 AutoScalingGroup hasn’t scaled EC2 Instances yet? You see the disconnect?
With “ECS Managed Cluster Auto Scaling”, this missing gap is now addressed. When your “Service” on ECS scales, ECS will dynamically adjust the “scaling policies” of the underlying EC2 AutoScalingGroup as well. Once EC2 scales and capacity is available, the “Tasks” would be automatically scheduled on them.
Note: This is pretty similar to ClusterAutoScaler in Kubernetes where it works alongside HorizontalPodAutoScaler. When there are more “Pods” that needs to be scheduled and there is no available underlying capacity, ClusterAutoScaler kicks in and scales the capacity. Pods will eventually gets scheduled automatically once capacity is available.
Closing Thoughts
On the ECS front, Capacity Providers and Managed Cluster Auto Scaling make it much more powerful and provides more control and flexibility. On the other hand, it does add a bit of complexity from a developer perspective. It still doesn’t come close enough to simply launching a container and getting an endpoint that is highly available and scales automatically.
On the EKS front, Fargate for EKS is the right step towards offering a “serverless” Kubernetes service. I liked the fact that you can continue to use Kubernetes “primitives” such as Pod/Deployment and you can control using “Fargate Profile” to selectively schedule Pods to Fargate. This is a different direction from GCP’s Cloud Run which can simply take a Container Image and turn it into an endpoint.
I am assuming AWS will continue to iterate in this space and address all the gaps. Looking at the plethora of options available, it appears that AWS wants to address different types of container use cases coming out of its vast customer base.
ECS Vs Kubernetes
And looking at the iterations and features on ECS, it looks like ECS continues to see customer adoption despite the gaining popularity of Kubernetes. AWS doesn’t iterate on services when it doesn’t see enough customer adoption. Remember SimpleDB? Simple Work Flow? Elastic Transcoder? Amazon Machine Learning?
Whenever they don’t see enough traction, AWS is quick to pivot to newer services and rapidly iterate (they would still operate and support older services). The continued iterations on both ECS and EKS front suggests that there is currently a market for both the orchestration engines. Only time would tell if it would be otherwise.
Well those are the announcements that I found interesting in the area of Containers. Did I miss anything? Let me know in the comments.


